
Come funziona e cosa è la Batch Normalization
Il problema centrale che la Batch Normalization (BN) mira a risolvere nel campo del deep learning è noto come “internal covariate shift”. Per comprendere appieno l’importanza di questa soluzione, è cruciale analizzare la natura del problema e il modo in cui la BN agisce efficacemente per mitigarlo.
Che Cos’è l’Internal Covariate Shift?
L’internal covariate shift si riferisce alle variazioni nella distribuzione degli input dei vari strati di una rete neurale durante il processo di training. Man mano che la rete si adatta e apprende dai dati, i pesi e i bias degli strati si aggiornano, causando una variazione continua delle distribuzioni degli input ricevuti dagli strati successivi. Questo fenomeno impone a ogni strato della rete di adattarsi costantemente a nuove distribuzioni, rallentando la convergenza del modello e rendendo più difficile il processo di training.
Perché l’Internal Covariate Shift è un Problema?
Il continuo cambiamento delle distribuzioni di input rende complicato per la rete stabilizzare l’apprendimento, poiché gli strati devono continuamente adattarsi a nuove condizioni. Questo non solo rallenta il training, ma rende anche più complessa la sintonizzazione dei parametri della rete, come il tasso di apprendimento e l’inizializzazione dei pesi. Inoltre, può portare a problemi di saturazione nelle funzioni di attivazione (ad esempio, nelle funzioni sigmoide e tanh), dove valori di input troppo elevati o troppo bassi riducono la sensibilità della rete alle variazioni dei dati di input.
Come Funziona la Batch Normalization?
La Batch Normalization affronta il problema dell’internal covariate shift normalizzando gli input di ciascun strato per ogni batch di dati. In pratica, questo significa regolare gli input degli strati in modo che abbiano una media prossima a zero e una varianza unitaria. Questo processo stabilizza le distribuzioni degli input per gli strati successivi, permettendo alla rete di apprendere in modo più efficiente.
Il processo di BN segue questi passaggi:
1.Calcolo della Media e della Varianza: Per ogni batch di dati, la BN calcola la media e la varianza degli input di uno strato.
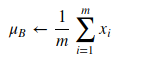
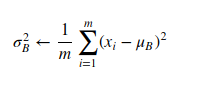
2. Normalizzazione: Gli input vengono poi normalizzati sottraendo la media e dividendo per la radice quadrata della varianza aggiunta di un piccolo termine epsilon, per evitare la divisione per zero.
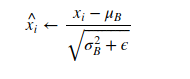
3. Riscalamento e Traslazione: Infine, gli input normalizzati vengono riscalati e traslati attraverso i parametri appresi 
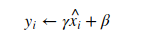
dove y è il valore normalizzato prodotto da ogni sub-strato della rete che passerà attraverso la funzione di attivazione, quali Sigmoide, Relu, Tanh ecc ecc.
Questi passaggi consentono alla BN di mantenere la capacità della rete di rappresentare le funzioni non-lineari,
Vantaggi della Batch Normalization
La stabilizzazione delle distribuzioni di input attraverso la BN porta a numerosi vantaggi:
- Accelerazione del Training: Riducendo l’internal covariate shift, la BN permette di usare tassi di apprendimento più elevati senza il rischio di divergenza, accelerando significativamente il training.
- Miglioramento dell’Inizializzazione: Con la BN, la rete diventa meno sensibile all’inizializzazione dei pesi.
- Utilizzo Efficiente di Funzioni di Attivazione Non-Lineari: La BN riduce il rischio di saturazione per funzioni di attivazione come la sigmoide, permettendo di costruire reti neurali più profonde.
- Effetto di Regolarizzazione: La BN introduce un leggero effetto di regolarizzazione, potenzialmente riducendo la necessità di altre tecniche come il dropout.

Sono amante della tecnologia e delle tante sfumature del mondo IT, ho partecipato, sin dai primi anni di università ad importanti progetti in ambito Internet proseguendo, negli anni, allo startup, sviluppo e direzione di diverse aziende; Nei primi anni di carriera ho lavorato come consulente nel mondo dell’IT italiano, partecipando attivamente a progetti nazionali ed internazionali per realtà quali Ericsson, Telecom, Tin.it, Accenture, Tiscali, CNR. Dal 2010 mi occupo di startup mediante una delle mie società techintouch S.r.l che grazie alla collaborazione con la Digital Magics SpA, di cui sono Partner la Campania, mi occupo di supportare ed accelerare aziende del territorio .
Attualmente ricopro le cariche di :
– CTO MareGroup
– CTO Innoida
– Co-CEO in Techintouch s.r.l.
– Board member in StepFund GP SA
Manager ed imprenditore dal 2000 sono stato,
CEO e founder di Eclettica S.r.l. , Società specializzata in sviluppo software e System Integration
Partner per la Campania di Digital Magics S.p.A.
CTO e co-founder di Nexsoft S.p.A, società specializzata nella Consulenza di Servizi in ambito Informatico e sviluppo di soluzioni di System Integration, CTO della ITsys S.r.l. Società specializzata nella gestione di sistemi IT per la quale ho partecipato attivamente alla fase di startup.
Sognatore da sempre, curioso di novità ed alla ricerca di “nuovi mondi da esplorare“.
Comments