
Reinforcement learning – Apprendimento con rinforzo : seconda parte
Prima di approcciare al modello matematico del Q-learning ritengo sia utile, per chi non ne abbia consoscenza, introdurre alcuni concetti strettamente correlati con i meccanimi di apprendimento con rinforzo; ovvero i processi decisionali di Markov (MDP) che costituiscono la base teorica del modello che vedremo dopo.
Processi markoviani
Un processo markoviano (o di Markov) è un processo aleatorio in cui la probabilità di transizione che determina il passaggio a uno stato di sistema dipende solo dallo stato del sistema immediatamente precedente (proprietà di Markov) e non da come si è giunti a questo stato.
Immagino che questa definizione non abbia aggiunto molto alla comprensione del concetto ed al nostro discorso, ma per i nostri futuri scopi è utile ricordarla; in pratica quando mi trovo in una situazione (stato) il fatto che io possa cambiarla ( tra le le diverse possibili e casuali ) dipende solo dalla situazione in cui mi trovo e non devo tenere in cosiderazione di tutto quello che ho fatto prima. In pratica è come se facessi delle scelte senza avere memoria di quello che ho fatto in passato, ma avendo solo conoscenza di quello che sto facendo.
Catena di Markov
Bene a questo punto possiamo complicare un pò le cose e possiamo introdurre anche il concettto di catena di Markov omogenea che possiamo definire formalmente così:
Una catena di Markov omogenea è un processo markoviano in cui la probabilità di transizione al tempo non dipende dal tempo stesso, ma soltanto dallo stato del sistema al tempo immediatamente precedente . In altre parole, la probabilità di transizione è indipendente dall’origine dell’asse dei tempi e quindi dipende soltanto dalla distanza tra i due istanti temporali.

 . In altre parole, la probabilità di transizione è indipendente dall’origine dell’asse dei tempi e quindi dipende soltanto dalla distanza tra i due istanti temporali.
. In altre parole, la probabilità di transizione è indipendente dall’origine dell’asse dei tempi e quindi dipende soltanto dalla distanza tra i due istanti temporali.Il concetto è sempre lo stesso, ma formalmente definito nel tempo, questa definizione ci aiuta perchè una catena di Markov omogenea a stati finiti può essere rappresentata mediante una matrice di transizione A. Una matrice ad esempio 3X3 rappresenta una catena Markoviana con 9 stati possibili.
Prendendo in esame la matrice precedente, possiamo dire che gli elementi di A rappresentano le probabilità di transizione tra gli stati della catena, pertanto una catena che si trova nello stato i ha probabilità di passare allo stato j nel passo immediatamente successivo, mentre gli elementi che stanno sulla diagonale della matrice indicano le probabilità di rimanere nello stesso stato i.


Tentiamo a questo punto di affrontare il tema dell’apprendimento con rinforzo approcciando al metodo oggetto dell’articolo : Q-Leaning.
Q-Learning
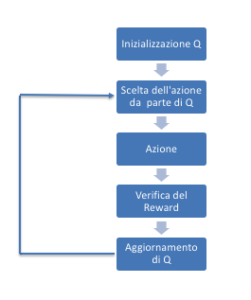
Come anticipato in precendenza il modello prevede l’introduzione di un agente in grado di osservare l’ambiente e di efftettuare delle azioni; in tal senso il modello agente / ambiente è modellabile attraverso un insieme di stati S e un insieme di azioni per stato A. Il modello pertanto funzionerà nel seguente modo:
Effettuando un’azione l’agente si sposterà da uno stato ad un altro stato ed ad ogni ogni cambiamenteo di stato verrà fornita all’agente una ricompensa (un numero reale o naturale), mentre l’obiettivo dell’agente sarà quello di massimizzare la ricompensa totale.
L’agente, pertanto, continuerà ad esplorare apprendendo le azioni ottimali associate ad ogni stato.
In definitiva l’algoritmo di Q-Leanring definisce il modo per calcolare la Qualità di una coppia stato-azione:

In fase iniziale Q restituirà un valore fisso, definito a piacere in fase di inzializzazione dell’algorittimo, successivamente, ogni volta che l’agente riceverà una ricompensa (quindi ad ogni cambiamento di stato ) verranno ricalcolati nuovi valori per ogni combinazione stato-azione. Il cuore dell’algoritmo fa uso di un processo iterativo di aggiornamento e correzione basato sulla nuova informazione.
![{\displaystyle Q(s_{t},a_{t})\leftarrow \underbrace {Q(s_{t},a_{t})} _{\rm {vecchio~valore}}+\underbrace {\alpha _{t}(s_{t},a_{t})} _{\rm {tasso~di~apprendimento}}\times \left[\overbrace {\underbrace {R_{t+1}} _{\rm {ricompensa}}+\underbrace {\gamma } _{\rm {fattore~di~sconto}}\underbrace {\max _{a_{t+1}}Q(s_{t+1},a_{t+1})} _{\rm {valore~futuro~massimo}}} ^{\rm {valore~appreso}}-\underbrace {Q(s_{t},a_{t})} _{\rm {vecchio~valore}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/396693dbead4db59875f5a5cfc757c41eb7d5fe6)
dove è una ricompensa osservata dopo aver eseguito in , e il tasso di apprendimento (o learning rate) è identificato da ). Il fattore di sconto è tale che







La formula sopra è equivalente a:
![{\displaystyle Q(s_{t},a_{t})\leftarrow Q(s_{t},a_{t})(1-\alpha _{t}(s_{t},a_{t}))+\alpha _{t}(s_{t},a_{t})[R_{t+1}+\gamma \max _{a_{t+1}}Q(s_{t+1},a_{t+1})]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4c5cd7734788017f15bb8478f7fd8a3132f779c8)
Un episodio dell’algoritmo termina quando lo stato è uno stato finale (o stato di assorbimento).
 è uno stato finale (o stato di assorbimento).
è uno stato finale (o stato di assorbimento).Notare che per tutti gli stati finali , non viene mai aggiornato e quindi conserva il suo valore iniziale.


N.B. Il tasso di apprendimento determina con quale estensione le nuove informazioni acquisite sovrascriveranno le vecchie informazioni. Un fattore 0 impedirebbe all’agente di apprendere, al contrario un fattore pari ad 1 farebbe sì che l’agente si interessi solo delle informazioni recenti.
N.B. Il fattore di sconto determina l’importanza delle ricompense future. Un fattore pari a 0 renderà l’agente “opportunista” facendo sì che consideri solo le ricompense attuali, mentre un fattore tendente ad 1 renderà l’agente attento anche alle ricompense che riceverà in un futuro a lungo termine.

Sono amante della tecnologia e delle tante sfumature del mondo IT, ho partecipato, sin dai primi anni di università ad importanti progetti in ambito Internet proseguendo, negli anni, allo startup, sviluppo e direzione di diverse aziende; Nei primi anni di carriera ho lavorato come consulente nel mondo dell’IT italiano, partecipando attivamente a progetti nazionali ed internazionali per realtà quali Ericsson, Telecom, Tin.it, Accenture, Tiscali, CNR. Dal 2010 mi occupo di startup mediante una delle mie società techintouch S.r.l che grazie alla collaborazione con la Digital Magics SpA, di cui sono Partner la Campania, mi occupo di supportare ed accelerare aziende del territorio .
Attualmente ricopro le cariche di :
– CTO MareGroup
– CTO Innoida
– Co-CEO in Techintouch s.r.l.
– Board member in StepFund GP SA
Manager ed imprenditore dal 2000 sono stato,
CEO e founder di Eclettica S.r.l. , Società specializzata in sviluppo software e System Integration
Partner per la Campania di Digital Magics S.p.A.
CTO e co-founder di Nexsoft S.p.A, società specializzata nella Consulenza di Servizi in ambito Informatico e sviluppo di soluzioni di System Integration, CTO della ITsys S.r.l. Società specializzata nella gestione di sistemi IT per la quale ho partecipato attivamente alla fase di startup.
Sognatore da sempre, curioso di novità ed alla ricerca di “nuovi mondi da esplorare“.
Comments