
Come è fatta una rete neurale (terza parte)
Entriamo nel vivo delle reti neurali, lasciandoci alle spalle le metodologie statistiche per passare piano piano alle nuove frontiere dell’apprendimento automatico. Prima di inziare a complicarci la vita con qualche nuova nozione matematica un pò più complessa, facciamo prima di tutto un excursus sui concetti basi che bisogna assolutamente conoscere. Partiamo pertanto dai concetti già accennati nel primo articolo. Il neurone artificiale è ” l’unità” di base ovvero l’elemento da cui partire per costruire una DNN ( Deep Neural Network ) ed è un elemento matematico che si “attiva” solo se si verificano determinate condizioni in ingresso.

In sintesi l’espressione matematica di un neurone artificiale si può riassumere come somma di valori moltiplicati per dei parametri (w) che vengono chiamati pesi.

Nel caso esemplificativo di un neurone a tre ingressi si ha ad esempio una espressione molto semplice:

di cui la rappresentazione matematica è la seguente:
![]()
Come si può notare dalla formula generalizzata del neurone , esso è caratterizzato da una funzione f di attivazione in uscita, la cui variazione implica un cambiamento sensibile del comportamento del neurone stesso. Possiamo, a questo punto, iniziare a fare qualche piccola precisazione ed introdurre la differenza tra percettrone e neurone sigmoidale. La differenza, come si può immaginare, è nella funzione di attivazione che nel caso del percettrone è una funzione a gradino :
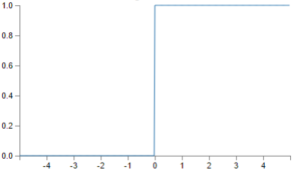
mentre nel secondo caso è una sigmoide
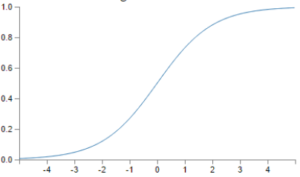
Come accennato, il cambiamento della funzione di attivazione, fa variare sostanzialmente il comportamento del neurone e di conseguenza della rete neurale di cui fa parte. Il percettrone, infatti, si attiva solo se la somma pesata dei valori di ingresso supera una certa soglia ed in tal caso l’uscita assume un valore uguale ad 1 mentre nel caso opposto il percettrone resta inattivo restituendo valore 0.

Nel caso del neurone sigmoidale, l’uscita può assumere valori compresi tra 0 ed 1 in rispetto della seguente funzione :

Di questi argomenti ne riparleremo comunque, in dettaglio, in altri articoli e per completare il quadro ricordo che esistono altre tipi di funzioni di attivazione usate; tra le più comuni abbiamo le lineari e le relu.
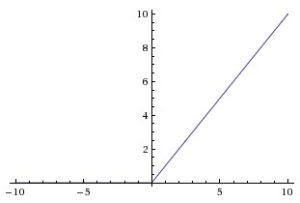
In definitiva, al momento, basta ricordare che è possibile modellare neuroni artificiali sensibilmente diversi al variare della funzione di attivazione.
Che cosa è dunque una rete neurale?
La risposta a questo punto penso sia alquanto scontata; di fatto una rete neurale è una struttura più o meno complessa di neuroni collegati tra di loro, secondo schemi e modelli di natura diversa.
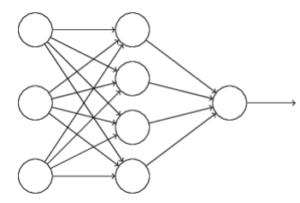
Nell’esempio di figura ci troviamo difronte una rete neurale a tre ingressi ed una sola uscita.

Lo strato più a sinistra è chiamato input layer (strato di input). Lo strato più a destra è chiamato output layer (strato di output). Lo strato di mezzo è invece detto hidden layer (strato nascosto) e può essere complesso a piacere.

Ovviamente i neuroni che costiuiscono la rete possono essere di tipo diverso. Le reti neurali, del tipo in figura, in cui l’output di uno strato è utilizzato come input per lo strato successivo, sono chiamate reti feedforward e ciò significa che i neuroni dello stesso livello non possono comunicare tra loro ma possono inviare segnali solo allo strato successivo. In generale su reti di questo tipo non sono presenti strutture ciclicle, ovvero strati in cui l’output viene riutilizzato come input dello stesso livello, ma esistono reti che implementano strutture ricorsive che venogono chiamate reti RNN ( Recurrent Neural Network ).

Cerchiamo di differenziare le vari reti neurali imparando a distinguerle, ad esempio, per paradigmi di apprendimento:
- Apprendimento supervisionato
- Apprendomento non supervisionato
- Apprendimento per rinforzo
Il significato di apprendimento è legato esclusivamente al concetto del training ovvero del metodo scelto per istruire una rete neurale. Nel primo caso di apprendimento supervisionato di fatti la rete viene istruita partendo dal concetto che ad ogni informazione fornita in ingresso, si conosce preventivamente il risultato atteso. Un esempio tipico nella vita reale è dell’alunno che impara grazie alla supervisione del maestro che già è informato sui risultati. Le reti neurali di questo tipo sono spesso usate per risolvere problemi di classificazione. Se si volesse ad esempio far capire ad una rete neurale la differenza tra un cane ed un gatto dovremmo fornire alla stessa un set di informazioni di “gatti” ed un set di informazioni di “cani”, specificando cosa è un gatto e cosa è un cane ( label o classe). Il training della rete consiste, pertanto, da un punto di vista matematico/algoritmico nella scelta di tutti i pesi w che minimizzano la funzione di costo. A tal proposito bisogna introdurre il concetto di back propagation dell’errore, di cui parleremo in seguito, ma che in sostanza costuisce lo strumento per consentire alla rete neurale di evolvere ed imparare. Il training della rete termina con la realizzazione di un modello matematico che può essere usato, succesivamente, per lo scopo progettato ed il grado di affidabilità delle stessa dipende da fattori diversi , come ad esempio:
- la complessità della rete neurale,
- il numero di neuroni impiegati
- qualità dell’addestramento a cui è soggetta.
Risulta infatti abbastanza semplice intuire che maggiore ad esempio è il numero di immagini di gatti e di cani che si riusciranno a fornire come esempio maggiore sarà la bontà dell’addestramento e di conseguenza la bontà della rete stessa, così come un cervello grande ( numero di neuroni) è sicuramente migliore di uno piccolo.
L’apprendimento non supervisionato è basato su algoritmi d’addestramento che modificano i pesi della rete, facendo esclusivamente riferimento ad un insieme di dati che coinvolgono solo le variabili d’ingresso (input) in quanto non si hanno a dispozione dati di riferimento ( classe ). L’apprendimento non supervisionato, pertanto è usato per clusterizzare input simili. Nel caso ad esempio di riconoscimento di immagini, una rete non supervisionata può lavorare per trovare similitudini tra oggetti raggruppando le stesse in cluster di somiglianza ( oggetto tondo, rosso … etc etc ) senza che la rete ne consosca di fatto il concetto intrinseco della similitudine ( oggetto tondo, rosso … etc etc ).
L’apprendimento per rinforzo (reinforcement learning), è implementato in una rete in grado di svolgere ad esempio funzioni predittive per individuare un comportamento e consentire alla stessa di effettuare delle scelte. La rete neurale in tal caso lavora partendo dall’osservazione dell’ambiente esterno in cui ogni azione ne modifica lo stato, producendo una retroazione ( feedback) che consente all’algoritmo di evolvere nel processo d’apprendimento.
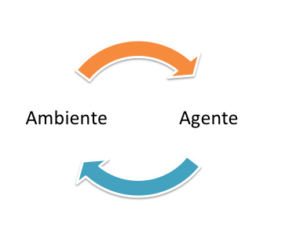
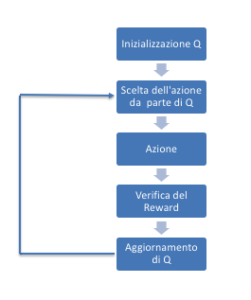
Un tipico esempio paragonato alla vita reale è l’addestramento di un cane a cui si da un premio nel caso in cui esso esegue un’azione corretta o un disincentivo nel caso contrario. Questo tipo di algorittimo prevede l’utilizzo di un agente, dotato di capacità di percezione, che esplora un ambiente nel quale intraprende una serie di azioni. L’apprendimento con rinforzo differisce da quello supervisionato poiché non sono previste per l’addestramento coppie input-output noti. Esempio di algorittimi di apprendimento per rinforzo sono implentati attraverso il metodo chiamato Q-Learning o Deep Q-Learning di cui parleremo nei prossimi articoli.
articolo precedente ( Seconda parte )
articolo successivo ( quarta parte )

Sono amante della tecnologia e delle tante sfumature del mondo IT, ho partecipato, sin dai primi anni di università ad importanti progetti in ambito Internet proseguendo, negli anni, allo startup, sviluppo e direzione di diverse aziende; Nei primi anni di carriera ho lavorato come consulente nel mondo dell’IT italiano, partecipando attivamente a progetti nazionali ed internazionali per realtà quali Ericsson, Telecom, Tin.it, Accenture, Tiscali, CNR. Dal 2010 mi occupo di startup mediante una delle mie società techintouch S.r.l che grazie alla collaborazione con la Digital Magics SpA, di cui sono Partner la Campania, mi occupo di supportare ed accelerare aziende del territorio .
Attualmente ricopro le cariche di :
– CTO MareGroup
– CTO Innoida
– Co-CEO in Techintouch s.r.l.
– Board member in StepFund GP SA
Manager ed imprenditore dal 2000 sono stato,
CEO e founder di Eclettica S.r.l. , Società specializzata in sviluppo software e System Integration
Partner per la Campania di Digital Magics S.p.A.
CTO e co-founder di Nexsoft S.p.A, società specializzata nella Consulenza di Servizi in ambito Informatico e sviluppo di soluzioni di System Integration, CTO della ITsys S.r.l. Società specializzata nella gestione di sistemi IT per la quale ho partecipato attivamente alla fase di startup.
Sognatore da sempre, curioso di novità ed alla ricerca di “nuovi mondi da esplorare“.
Comments